
Predicting Political Orientation From Twitter Data
Introduction
This summary report aims to find a connection between user’s twitter activity and their political affiliation. For the full report and code, please visit this link.
Abstract
In recent years, analyzing data acquired from social networks platform to predict and understand more about human cognition, behaviors and orientation has been a rising trend. Social media has changed not only the way we passively receive information but also how we express our personal opinions about everyday issues. That is the reason why Facebook, Twitter, Youtube and other social networks have become valuable sources of data that can be beneficial for many areas. Automatic political orientation prediction from social media posts has been proven successful in distinguishing between liberals and conservatives in the US. In this project, we will try to do political orientation prediction on Italian language and Italian political landscape.
Aim of The Analysis
The project consists of two main phases:
- We begin by crawling random Italian Twitter accounts (total 1000) and start labeling their favorite political parties (Lega, Partito Democratico, Fratelli d’Italia, Movimento 5 Stelle and Forza Italia) by going through their accounts. We do this 5 different times by 5 different group members, then calculating the marked party frequency for each account.
- In the second phase, we crawl all the tweets associated with those accounts. Data of classified Twitter accounts and tweet contents from different groups will be combined into one big dataset. Then we fix a threshold for political party labeling on each account then merge the newly downloaded data with the labeled account data from phase 1. The purpose of this phase is to train and test different classification models on the tweet contents to predict the political orientation “right vs left”. Lega, Fratelli d’Italia, and Forza Italia are considered as right wing while Partito Democratico is left wing. After training and testing the classification models, we will use them on the labeled data of Movimento 5 Stelle to see how they classify these accounts to “right” or “left”, since this party is controversial and difficult to classify left or right even for humans.
Initial Statistics
Before delving into the huge dataset that was generated from all of the groups, we decided to do some initial statistics analysis on the dataset that our group gathered. As shown in the plots bellow we gained insights on user twitter activity, user vocabulary and time period usage analysis.
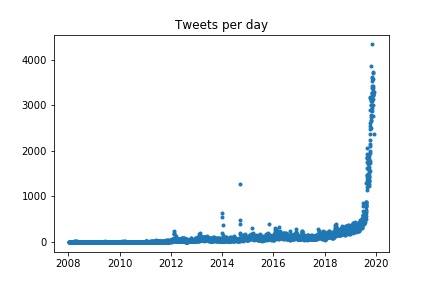
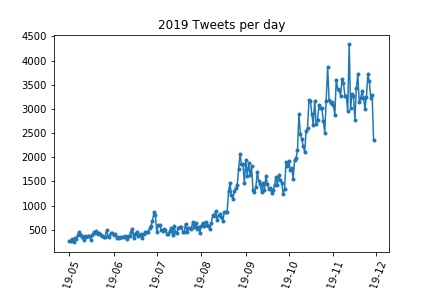
The plot clearly shows an almost exponential growth of number of tweets starting somewhere in the middle of August. A hypothesis can be formed that states this increase might be caused by the political crisis occurring in Italy during this period, given that twitter is known for beeing a place to express political opinion with a safe, anonymous profile.
In the following plot, we explore the length of the time periods in which the users were active on the site. More concretely, we compute the time difference between the first and last post of each user to determine what is the average time that a user is active on the site.
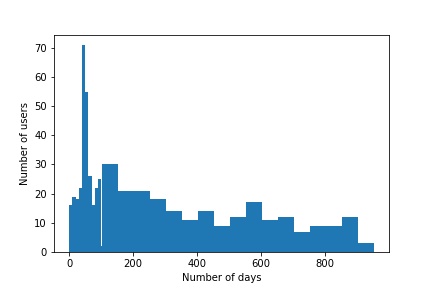
We can see that most of the users tend to use the platform for less than a 100 days while those that stay for a longer period are distributed uniformly. Another result we obtain before delving deeper into the data analysis and modeling is the fact that @matteosalvinimi is the 30th most used “word” in our dataset. Given the fact that we have a task to determine political affiliation from these tweets this is a motivating observation. A more detailed approach for how to obtain these results is available in the notebook.
Data Collection and Preparation
As already mentioned, our aim is to predict the political orientation of an Italian Twitter account chosen at random, using different machine learning models. For collecting the data, we used Tweepy – a Python library for accessing the Twitter API. This way, we were able to get information about 8000+ Italian Twitter Accounts, as well as their tweets.
Model Building
Once the data was nicely formatted, some models were built according to it. Data from users labeled by the majority as Lega, PD, FDI and FI is used to train models that predict the political orientation behind a tweet. The M5Star users were splitted into another file and not used to train the models. After building the models, at the end M5S supporters were classified by it to see whether they fell into one of the two categories.
Model Selection
We begin with a model among the multitude to see which one is the most convenient for our purpose. We take into account scores as accuracy, precision and recall but also computational simplicity, in order to make the part of fine tuning easier.
Parameter Fine-Tuning
After selecting the pipeline components of our model, we focused on improving their performance. This was done by removing stopwords and searching for the hyperparameters that yield best results.
Conclusion
The results were generated, as precedently stated, splitting the labelled users into a training set of 80% and a testing set of 20%. Between all models, the most successful one was the Random Forest Classifier, providing an accuracy of 91.16% with some fine tuning (removing stopwords, grid search on hyperparameters). The other good one has been the XGBoost, with an accuracy of 88.13%.